
前幾天講了 FAISS,講了 pgvector ,這類都不是真正專門的向量資料庫。FAISS 更像是一個套件,本身並不提供完整的資料庫功能,例如資料持久性、交易性和多用戶支持。而 pgvector 是一個 PostgreSQL 擴充套件,它為 PostgreSQL 資料庫添加了對高維向量的擴充,使我們能夠在一個成熟的關聯式資料庫環境中進行向量搜索和操作。然而,pgvector 也並不是一個專門為向量搜索或儲存而設計的資料庫,也常為人詬病的就是資料量一大,效能就會變差。因此,我們今天開始要來介紹的就是專門為了向量儲存與搜尋而誕生的資料庫。
現在向量資料庫百家爭鳴,目前最龍頭的可以說是 pinecone 了。Pinecone 是一個全託管的雲端服務,這代表開發人員可以不必擔心基礎架構和維護,省去了自設、管理和維護資料庫的需要。這對於可能沒有專門的運維或資料庫管理團隊的企業來說,可以節省大量時間和資源,更可以專注於 LLM 應用的開發。
然而,Pinecone 並不是開源的,也沒辦法在地端自己架設。有不少企業都有資料落地的需求,如果用 Pinecone 就無法滿足這個需求。我們後面還會繼續介紹幾個產品級的向量資料庫,不過會是開源並且可以在地端自己架設的。
值得注意的是,Pinecone 也有在三大公雲上面提供服務,不過我們今天的教學是讓大家先來嚕免錢的。

接著會問你一些問題,這裡你就隨便填吧!如下圖所示。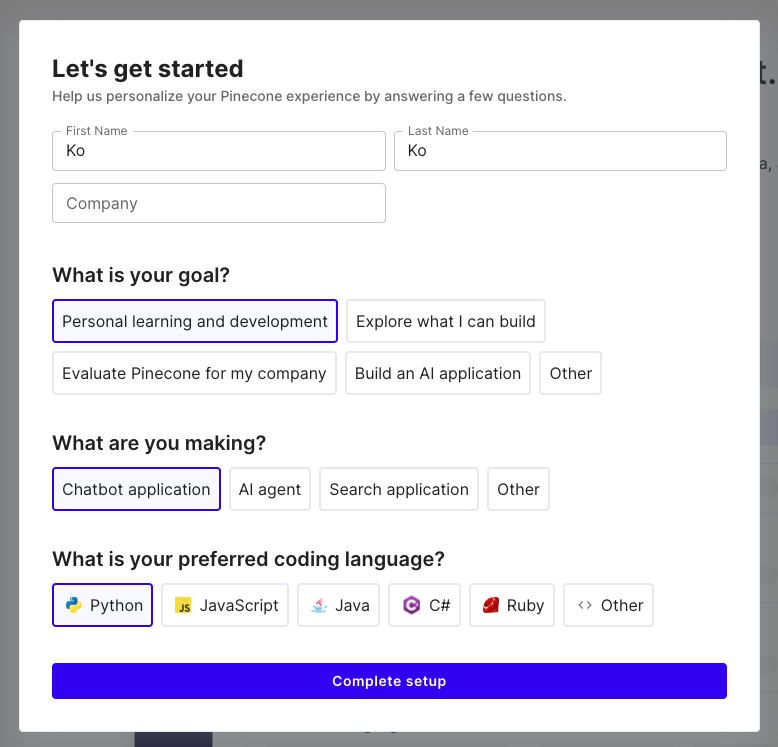
接著我們點擊畫面中間的 Create Index。如下圖所示。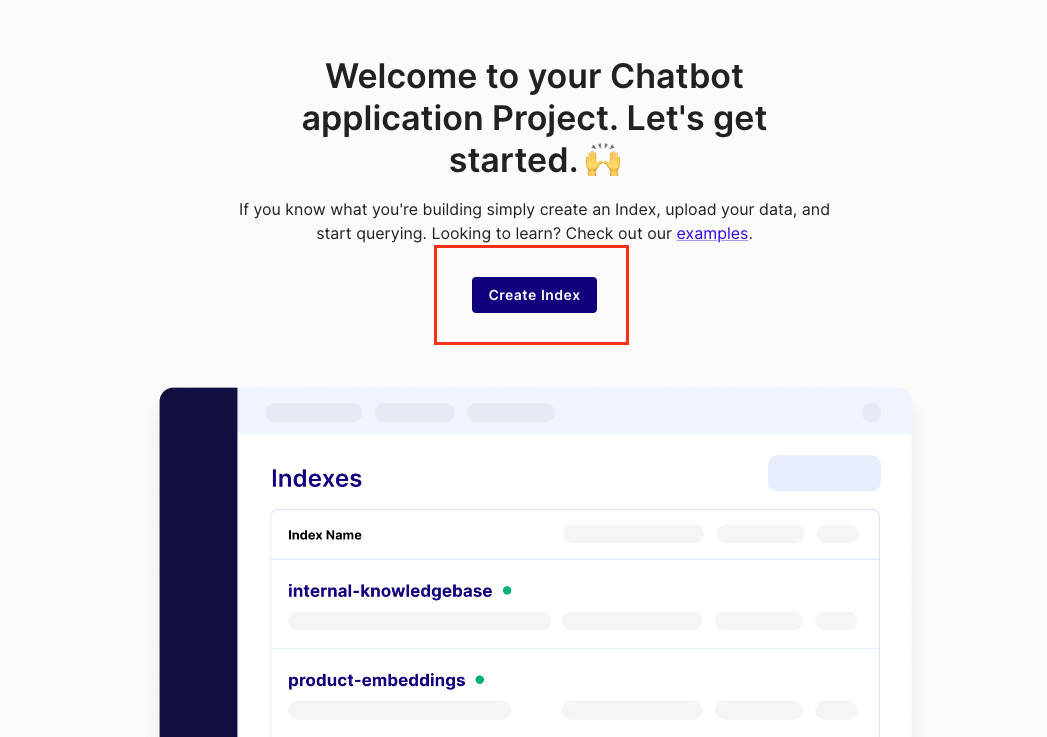
然後我們就來創建一個 pinecone 向量資料庫吧!需要注意的是 dimension 欄位,因為我們要用 OpenAI 的 text-embedding-ada-002,所以要填入 1536。如果你是要用其他的 embedding 模型,記得要填入對應的維度哦!而這裡的 ironman2023 在 Pinecone 稱為 index,是一個向量空間,我們可以簡單想成資料表的概念,我們會把許多的向量儲存在這個 index 裡面。如下圖所示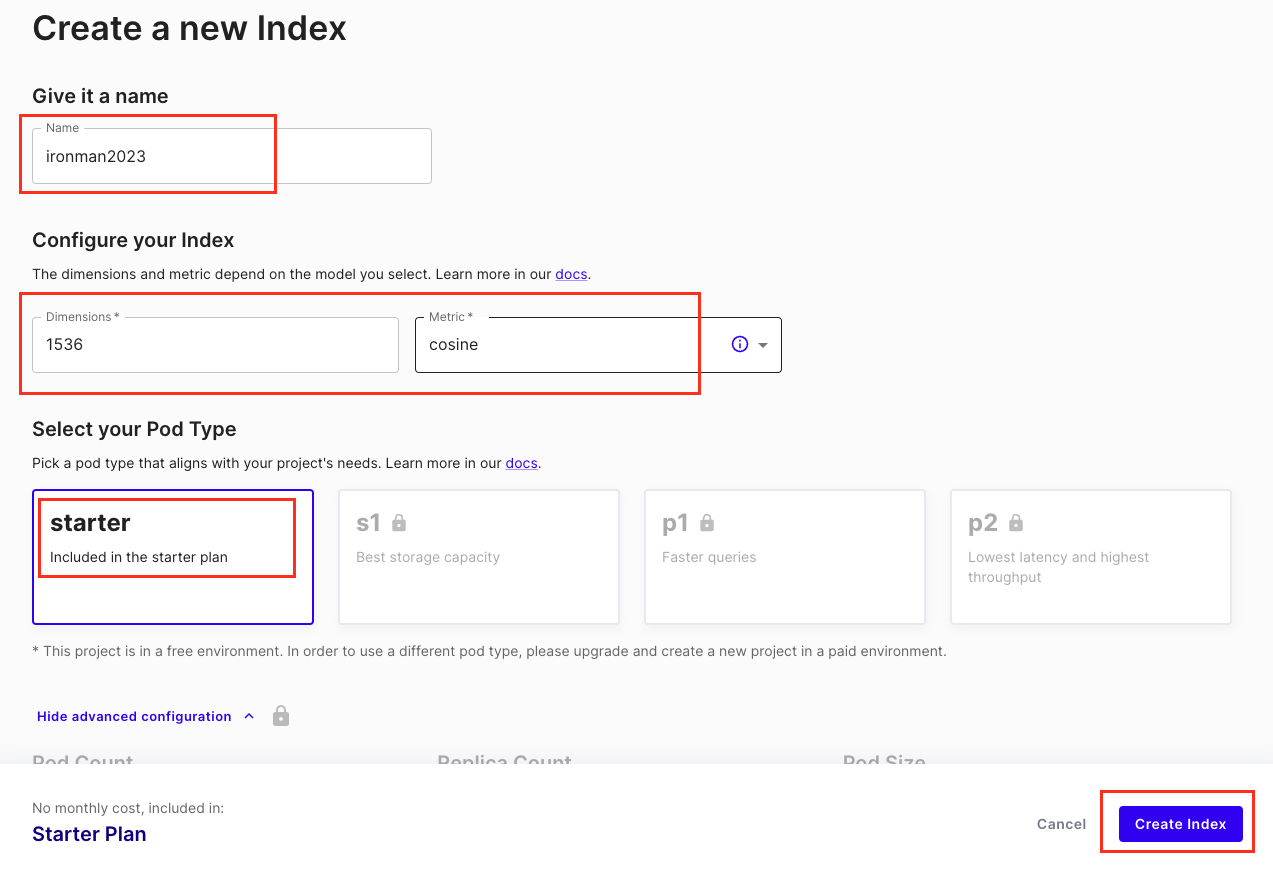
創建完成的話,我們就可以看到下面的畫面,把 HOST 欄位的網址儲存起來吧!如下圖所示。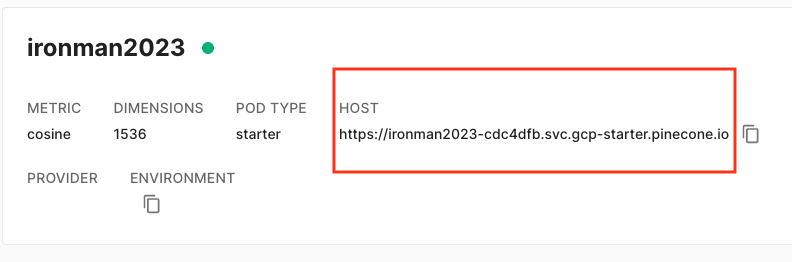
接著我們點左邊選單的 API Keys,可以看到我們的 API key,如下圖所示,這個也要存下來。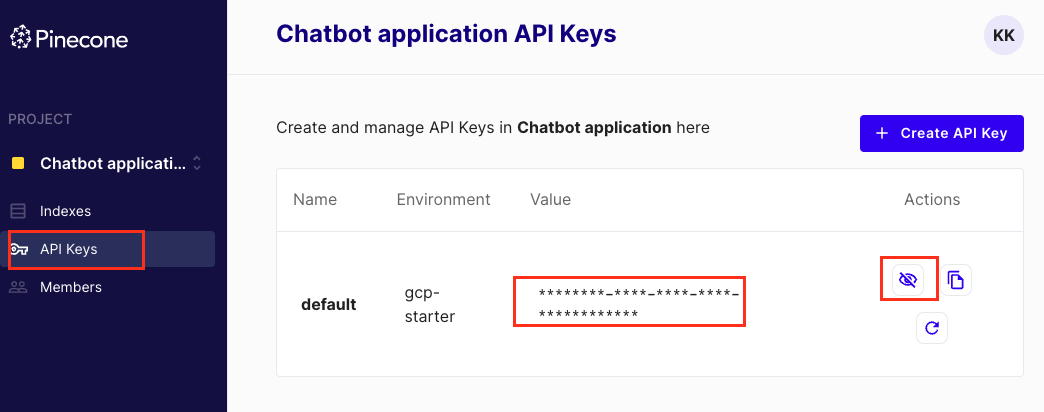
以上就完成 Pinecone 的基礎設定啦!明天我們就來開始用 SDK 來寫程式了。
